


報道官.jpg)

彼らが発表したグラフを引用しよう。
画像
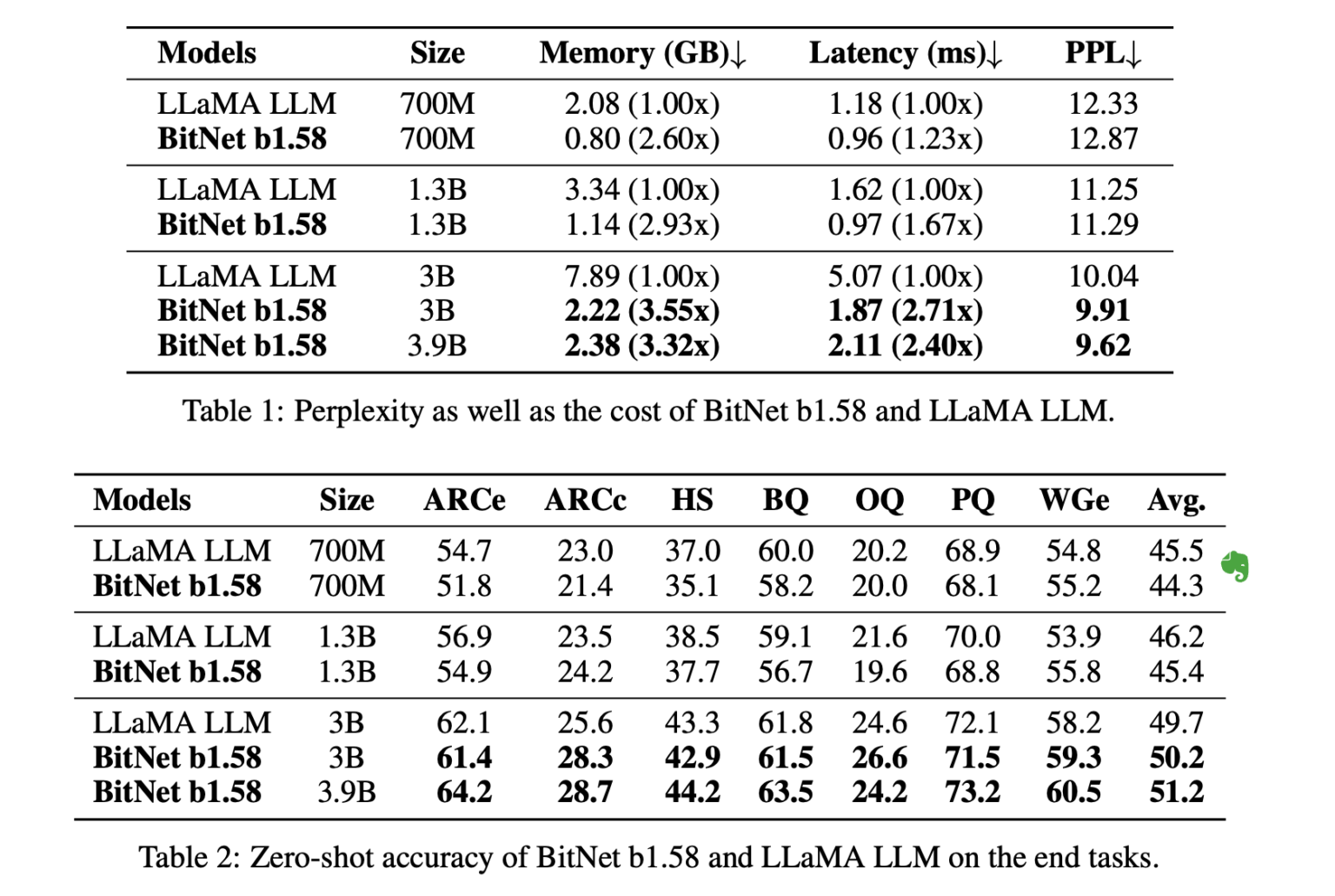
この表によると、BitNetはLlamaよりも3倍高速でしかも高精度ということになる。
この圧倒的なスピードの秘密は、BitNetが文字通り「1ビットで処理している」からだ。
通常、LLMをふくむディープラーニングされたニューラルネットは巨大な行列の積和演算(掛け算と足し算)を必要とする。
推論時も学習時もそうだ。
しかし、1ビット、つまり、行列の中身が0か1しかないのであれば、全ての計算を加算演算のみにできる。
加算と乗算では計算速度も負荷も段違いに異なるため、これだけのスピードの差が出ている。また、当然ながらメモリ効率も高い。
このため、この論文では「積和演算に最適化されたGPUではなく、加算処理のみに特化した新しいハードウェアの出現」までもが予言されている。
今現在、世界各国が血眼になってGPUを確保し、囲い込んでいることを考えると、実に痛快な論文だ。
詳細はソース 2024/2/28
https://news.goo.ne.jp/article/wirelesswire/business/wirelesswire-20240286094.html
Microsoftが1.58ビットの大規模言語モデルをリリース、行列計算を足し算にできて計算コスト激減へ
Microsoftの研究チームがモデルのウェイトを「-1」「0」「1」の3つの値のみにすることで大規模言語モデルの計算コストを激減させることに成功したと発表しました。
[2402.17764] The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
https://arxiv.org/abs/2402.17764
従来のモデルであれば入力に対して「0.2961」などのウェイトをかけ算してから足し引きする必要がありましたが、「-1」「0」「1」の3値のみであればかけ算が不要になり、全ての計算を足し算で行えるようになります。
今回の手法を利用することで行列演算に必要なかけ算の量を大幅に削減できるため、論文では「1bitの大規模言語モデル用の新たなハードウェア設計への扉を開く」と述べられています。
詳細はソース 2024/2/29
https://gigazine.net/news/20240229-microsoft-1bit-llm/
引用元: ・世界各国が血眼になってGPUを確保する中、とてつもないLLMがリリース、1ビットLLM 全ての推論を加算のみ GPU不要になる可能性も [お断り★]
ブレイクスルーレベルだはこんなの









コメント