




9/8(月) 7:00 アスキー(新清士)
https://news.yahoo.co.jp/articles/59d923f1ee59a4dc54bab2ee6b7db012762aca48
グーグルの画像AIモデル「Nano Banana(Gemini 2.5 Flash Image)」の性能の高さが話題を席巻しています。
写真:アスキー
https://ascii.jp/img/2025/09/08/4318160/l/183e7476d3589782.png
8月26日にリリースされたグーグルの画像AIモデル「Nano Banana(Gemini 2.5 Flash Image)」の性能の高さが話題を席巻しています。もとはAIのベンチマークサイト「LMArena」に、「nano-banana」という変な名前のモデルとして登場しました。とにかく、これまでの画像AIモデルと比べて、人物などの一貫性のレベルが段違いに高いという特徴があります。しかも、リリース後、商用版の「Gemini」だけでなく、テスト環境の「Google AI Studio」で、無料で使える環境を提供したこともあり、一般の人にまで利用や認知が広がりつつあります。また、その性能を探ろうと様々な試行錯誤がSNS上で繰り広げられています。
※記事配信先の設定によっては図版や動画等が正しく表示されないことがあります。その場合はASCII.jpをご覧ください
■人物描写の一貫性が異次元レベル
これまで画像生成AIは、人物描写で一貫性が維持しづらいという課題を抱えていました。人物の顔の向きを変えたり、服を変えたりすると、生成するたびに別人になってしまうことが問題でした。それを乗り越えようと「Flux.1 Kontext」など、様々なモデルが挑戦し、成果を上げていました。(参考:“一貫性”がすごい画像生成AI 冬服夏服も一発変換 話題の「FLUX.1 Kontext[dev]」 )
ところが、Nano Bananaはこれまでのモデルと品質が、異次元といえるレベルでの一貫性を実現しているのです。
いつも登場する作例AIモデル「明日来子さん」にいろいろな服に変身してもらいました。グーグルはAPI連携をさせたサンプルアプリとして、1枚の画像から時代別の画像を生成する「Past Forward」というアプリを公開していますが、それを使うと様々な時代の変化を生み出す画像を手軽に作れるのです。服装やポーズがそれぞれの年代に合わせて、出力されています。また、1980年代の画像を入力画像として「全身像にして写真の状態を維持したまま前、後ろ、横の三面図を作成してください」と指示すると、自然な雰囲気で出力されます。
明日来子さんの人物としての一貫性が、驚異的なレベルで維持されています。
https://ascii.jp/img/2025/09/08/4318161/l/d13719d4a88a1fd8.png
▲上記の画像を動画AI「Wan2.2 I2V」で繋いでみたもの。最初の白いTシャツ姿が入力画像。静止画の一貫性によって自然なつながりになっている
https://www.youtube.com/watch?v=H0B80iLLiaU
さらには、服装を変えたりということも簡単にできます。Midjourneyで作成した服装のサンプル画像を参照して、その服に変えてと指示すると、Tシャツ姿から自然に切り替わっています。また、両手を上げてダンスをしている様子とポーズを指示したり、傘を持って雨を降らせるようにと指示しても、そのシーンを構成して画像を生成してくれます。
■イラストもOK ポーズも自由に
画風は実写風もイラスト風も対応します。過去に作成した上半身イラスト風画像から、全身像を作成し、その角度を変えたり、笑顔でサインをするようにと指示をしたりしても、画風と一貫性を維持したまま追従してきます。また、同じ上半身画像から「表情集を作って」や「ポーズ集を作って」と指示すると、さすがに完璧に画風を真似はできてはいないのですが、手軽にバリエーションを作ってくれます。
最初のリファレンス画像(右)、全身像、全身像の回転、笑顔でサイン
https://ascii.jp/img/2025/09/08/4318165/l/73e376d77d1a01a8.png
「表情集を作って」「ポーズ集を作って」の結果。リファレンス画像は、上半身画像のみ
https://ascii.jp/img/2025/09/08/4318166/l/f4abe5afbfe993f7.png
引用元: ・【芸能】グーグルの画像生成AI「Nano Banana」は異次元レベル AIコンテンツの作り方を根本から変えた [湛然★]
さらにすごいのが、ポーズを取らせられる点です。
リファレンスとしてキャラクターの全身像をリファレンスとして入力し、さらにVRMモデル制作アプリ「VRM Posing Desktop」でマネキン状の3Dモデルのスクリーンショットを作成し、それを参照するようにと指示したところ、以下のようになりました。棒人間などの画像でも、参考ポーズとしての効果があることが確認されています。さらに、作成した動画を動画AIの開始フレームと終了フレームの機能でつなげば、一貫性を持ったキャラクターの自然なアニメーションを手軽に作ることができます。
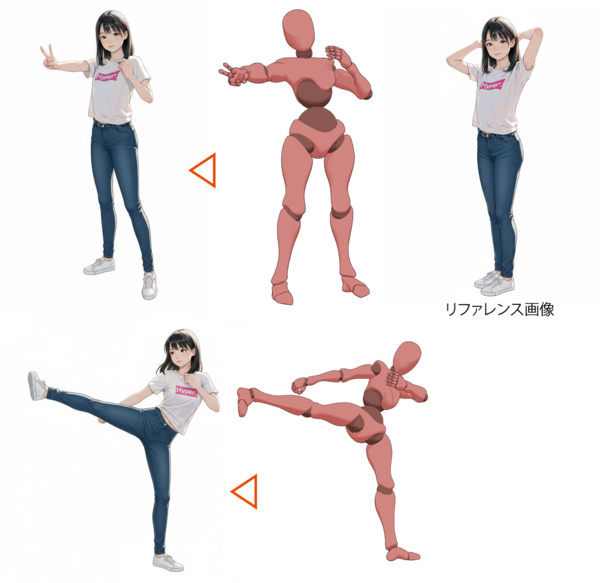
▲作成した画像を、Midjourney Videoでつなげてみたもの
https://www.youtube.com/watch?v=Rz-HJ4TtOwg
また話題になったものに、フィギュア化があります。実写でもイラストでも、プロンプトを入力するだけで、画像を本物が存在するかのように感じさせるフィギュアのようなものを生成することができます。AIイラストクリエイターのてんねんさんが開発したプロンプトは汎用性が高く、多くの人に利用されています。
(※以下略、全文は引用元サイトをご覧ください。)
意味ないよそんなの
マスピ顔を作ってた奴らは消えたのか?






コメント